Features¶
The following functions and classes are useful for extracting features from acoustic signals, such as time-frequency representations and linguistic features.
Auditory Spectrogram¶
- naplib.features.auditory_spectrogram(x, sfreq, frame_len=8, tc=4, factor='linear')[source]¶
Compute the auditory spectrogram of a signal using a model of the peripheral auditory system [1]. The model includes a cochlear filter bank of 128 constant-Q filters logarithmically-spaced, a hair cell model which includes a low-pass filter and a nonlinear compression function, and a lateral inhibitory network over the spectral axis. The envelope of each frequency band gives the time-frequency representation.
- Parameters:
x (np.ndarray) -- Acoustic signal to convert to time-frequency representation
sfreq (int) -- Sampling rate of the signal. This function is meant to be used on a signal with 16KHz sampling rate. If sfreq is different, it resamples the audio to 16KHz.
frame_len (float, default=8) -- Frame length of the output, in ms. Typically 8, 16, or a power of 2.
tc (float, default=4) -- Time constant for leaky integration. Must be >=0. If 0, then leaky integration becomes short-term average. Typically 4, 16, or 64 ms.
factor (float or string, default='linear') -- Nonlinear factor for hair cell model. If a positive float, specifies the critical level factor (typically 0.1 for a unit sequence). The smaller the value, the more the compression. Or, can be one of {'linear', 'boolean', 'half-wave'} describing the compressor.
- Returns:
aud -- Auditory spectrogram, shape (n_frames, 128).
- Return type:
np.ndarray
Notes
This is a python re-implementation of the Matlab function wav2aud in the NSLtools toolbox.
For correct performance, x should be a float array.
References
Examples using ``auditory_spectrogram ``¶
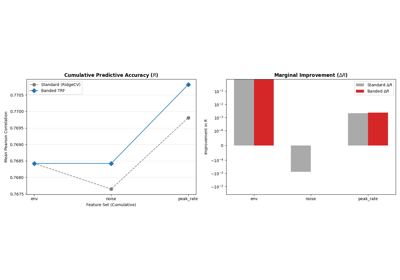
TRF Comparison: Iterative RidgeCV vs. Banded Regularization
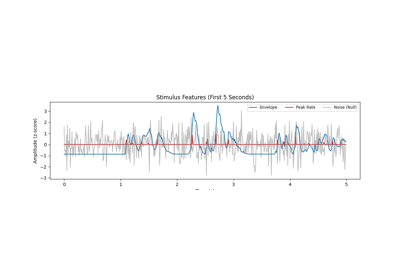


Extract peak_rate events from the Spectrogram¶
Aligner for Phonemes and Words¶
- class naplib.features.Aligner(output_dir, dictionary_file=None, tmp_dir=None)[source]¶
This class performs phoneme and word alignment using audio files and matching text files containing scripts. If words in the texts do not appear in the dict file, you will need to add them to a dict file and specify it as
dictionary_file.Note
Several extra packages are required to perform alignment. Please follow the installation instructions for
HTKandsoxfor your system before using alignment. Additionally, you will need to install pyyaml as well as TextGrid for the Aligner to work. These are not required dependencies of naplib-python, so they must be installed separately.- Parameters:
output_dir (string, path-like) -- Directory to put output files in, such as .phn, .wrd., and .TextGrid files.
dictionary_file (string, path-like, optional) -- Path to a dictionary file (e.g. eng.dict) which contains phonemes for all words in corpus. If not provided, will use the default eng.dict. For an example file, see ProsodyLab's eng.dict
tmp_dir (string, path-like, optional) -- Directory to hold temporary files that are created. If not provided, creates a folder called data_/ in the current working directory and uses that.
- align(data=None, name='name', sound='sound', soundf='soundf', transcript='transcript', dataf='dataf', length='length')[source]¶
Perform alignment across a set of paired audio-text files stored in fields of a Data object. This function will create a set of .TextGrid files, as well as corresponding .phn and .wrd files in the output_dir which describe the timing of phonemes and words within each audio. These files can be used in conjunction with the other functions in naplib.alignment, such as
get_phoneme_label_vectorandget_word_label_vector, which take these files as input. This function will automatically usenaplib.alignment.get_phoneme_label_vectorandnaplib.alignment.get_word_label_vectorto produce phoneme and word label vectors for each stimulus which can be placed into the Data object and further analyzed.This function is essentially equivalent to storing audio and text in directories and using
Aligner.align_filesfollowed byAligner.get_label_vecs_from_files.- Parameters:
data (Data instance) -- Data object containing the data to align. It must contain the following fields.
name (string or list of strings, default='name') -- If a string, specifies a field of the Data which contains the name for each trial. Otherwise, a list of strings specifies the name for each trial.
sound (string or list of np.ndarrays, default='sound') -- If a string, specifies a field of the Data which contains the sound waveform for each trial. Otherwise, a list of np.ndarrays specifies the waveform for each trial.
soundf (string, integer, or list of integers, default='soundf') -- If a string, specifies a field of the Data which contains the sampling rate for each trial. Otherwise, a list of integers specifies the sampling rate for each trial, or a single integer gives the sampling rate for all trials.
transcript (string or list of strings, default='transcript') -- If a string, specifies a field of the Data which contains the transcript text for each trial. Otherwise, a list of strings specifies the transcript text for each trial.
dataf (string, integer, or list of integers, default='dataf') -- If a string, specifies a field of the Data which contains the desired sampling rate of the output. Otherwise, a list of integers specifies the Desired sampling rate of the output for each trial, or a single integer gives the desired sampling rate of the output for all trials.
length (string or list of integers, default='length') -- If a string, specifies a field of the Data which contains the desired output length (in samples) for each trial. Otherwise, a list of integers specifies the desired output length (in samples) for each trial.
- Returns:
alignment_data (Data instance) -- Data object containing all alignment information, with all the fields described by the return values below.
phn_labels (list of np.ndarrays) -- Phoneme label vector for each trial. alignment_data['phn_labels'][i] is a np.ndarray of shape (time,) and sampling rate dataf[i].
manner_labels (list of np.ndarrays) -- Manner of articulation label vector for each trial. alignment_data['manner_labels'][i] is a np.ndarray of shape (time,) and sampling rate dataf[i].
wrd_labels (list of np.ndarrays) -- Word label vector for each trial. alignment_data['wrd_labels'][i] is a np.ndarray of shape (time,) and sampling rate dataf[i].
phn_label_list (list of lists of strings) -- Phoneme label list returned by
naplib.alignment.get_phoneme_label_vector, so alignment_data['phn_label_list'][i] is a list of phonemes, where the index of a given phoneme in the list encodes that phoneme's label inphn_labels.manner_label_list (list of lists of strings) -- Manner of articulation label list returned by
naplib.alignment.get_phoneme_label_vector, so alignment_data['manner_label_list'][i] is a list of manners, where the index of a given manner in the list encodes that manner's label inmanner_labels.wrd_dict (dict) -- Dictionary of word:int (key:value) pairs for all the words in the corpus of files in the directory, created by
naplib.alignment.create_wrd_dictSo, alignment_data['wrd_dict'][i] is a dictionary which maps a word to its integer value as it is represented inwrd_labels.
Note
This function will produce the following files in the output_dir to aid in its running.
working directory└── output_dir│ └── trial1.phn│ └── trial1.wrd│ └── trial1.TextGrid│ └── trial2.phn│ └── trial2.wrd│ └── trial2.TextGrid
- align_files(audio_dir, text_dir, names=None)[source]¶
Perform alignment across a set of paired audio-text files stored in directories. This function will create a set of .TextGrid files, as well as corresponding .phn and .wrd files in the output_dir which describe the timing of phonemes and words within each audio. These files can be used in conjunction with the other functions in naplib.alignment, such as
get_phoneme_label_vectorandget_word_label_vector, which take these files as input.- Parameters:
audio_dir (string, path-like) -- Directory containing audio files (.wav).
text_dir (string, path-like) -- Directory containing text files (.txt) with matching names to the files in
audio_dir.names (list of strings, optional) -- List of names (without file-type) which specify a subset of files within .the audio_dir and text_dir to process.
Note
The directory structure containing audios and matching text files must be correct in order to properly perform alignment. See below for what the directory layout should look like before running this function.
working directory├── audio_dir│ ├── file1.wav│ ├── file2.wav└── text_dir│ └── file1.txt│ └── file2.txtAfter running this function, the directory layout will look like this:
working directory├── audio_dir│ ├── file1.wav│ ├── file2.wav└── text_dir│ └── file1.txt│ └── file2.txt└── output_dir│ └── file1.phn│ └── file1.wrd│ └── file1.TextGrid│ └── file2.phn│ └── file2.wrd│ └── file2.TextGrid
- get_label_vecs_from_files(data=None, name='name', dataf='dataf', length='length', befaft='befaft')[source]¶
- Parameters:
data (Data instance) -- Data object containing the data to align. It must contain the following fields.
name (string or list of strings, default='name') -- If a string, specifies a field of the Data which contains the name for each trial. Otherwise, a list of strings specifies the name for each trial.
dataf (string, integer, or list of integers, default='dataf') -- If a string, specifies a field of the Data which contains the desired sampling rate of the output. Otherwise, a list of integers specifies the Desired sampling rate of the output for each trial, or a single integer gives the desired sampling rate of the output for all trials.
length (string or list of integers, default='length') -- If a string, specifies a field of the Data which contains the desired output length (in samples) for each trial. Otherwise, a list of integers specifies the desired output length (in samples) for each trial.
befaft (string or list of np.ndarrays, or a single np.ndarray, default='befaft') -- If a string, specifies a field of the Data which contains the before and after time (in sec) for each trial. Otherwise, a list should contain the befaft period for each trial, and a single np.ndarray of length 2 specifies the befaft period for all trials. For example, befaft=np.array([0.5, 0.5]) indicates that for each trial, the wav file which was used to produce the alignment is 0.5 seconds shorter at the beginning and 0.5 seconds shorter at the end than the desired output length.
- Returns:
alignment_data (Data instance) -- Data object containing all alignment information, with all the fields described by the return values below.
phn_labels (list of np.ndarrays) -- Phoneme label vector for each trial. alignment_data['phn_labels'][i] is a np.ndarray of shape (time,) and sampling rate dataf[i].
manner_labels (list of np.ndarrays) -- Manner of articulation label vector for each trial. alignment_data['manner_labels'][i] is a np.ndarray of shape (time,) and sampling rate dataf[i].
wrd_labels (list of np.ndarrays) -- Word label vector for each trial. alignment_data['wrd_labels'][i] is a np.ndarray of shape (time,) and sampling rate dataf[i].
phn_label_list (list of lists of strings) -- Phoneme label list returned by
naplib.alignment.get_phoneme_label_vector, so alignment_data['phn_label_list'][i] is a list of phonemes, where the index of a given phoneme in the list encodes that phoneme's label inphn_labels.manner_label_list (list of lists of strings) -- Manner of articulation label list returned by
naplib.alignment.get_phoneme_label_vector, so alignment_data['manner_label_list'][i] is a list of manners, where the index of a given manner in the list encodes that manner's label inmanner_labels.wrd_dict (dict) -- Dictionary of word:int (key:value) pairs for all the words in the corpus of files in the directory, created by
naplib.alignment.create_wrd_dictSo, alignment_data['wrd_dict'][i] is a dictionary which maps a word to its integer value as it is represented inwrd_labels.
Note
This function requires that the following files ALREADY exist in the aligner's output_dir.
working directory└── output_dir│ └── trial1.phn│ └── trial1.wrd│ └── trial1.TextGrid│ └── trial2.phn│ └── trial2.wrd│ └── trial2.TextGrid
Phoneme Labels from Phonetic Alignment File¶
- naplib.features.get_phoneme_label_vector(phn_file, length, fs, befaft, mode='phonemes', return_label_lists=False)[source]¶
Creates a time-series vector of phoneme labels based on the output of the Penn-Phonetic Alignment procedure.
Returns label vector as numpy array of shape (time, ) containing categorical labels. Assumes that the .phn files were made on wav files that did not have a befaft zero period.
This function can be used instead of the
get_label_vecs_from_filesmethod inside theAlignerclass if you only want a single file's label vector.- Parameters:
phn_file (string, path to .phn file)
length (int, length of stimulus (in samples) including befaft periods)
fs (int, sampling rate)
befaft (array or list of length 2, containing befaft time periods in seconds)
mode (string, either 'phonemes', or 'manner'. Any empty or 'sp' periods are labeled -1.) -- If 'manner': labels correspond to ['plosive','fricative','nasal','sonorant']
return_label_lists (bool, if True, returns a 2-tuple containing the labels as well as the list) -- of possible labels, so that the index of a label in the list is the integer label assigned to it.
- Returns:
labels (np.array, shape (time,)) -- Integer labels over time. Full length is befaft[0]*fs+length+befaft[1]*fs
item_list (list) -- List of phonemes (if mode=='phonemes') or manners of articulation (if mode=='manner') which were used. The index of a phoneme indicates the label it is assigned.
Word Labels from Word Alignment File¶
- naplib.features.get_word_label_vector(wrd_file, length, fs, befaft, wrd_dict=None, wrd_files_dir=None, return_wrd_dict=False)[source]¶
Returns label vector as numpy array of shape (time, ) containing categorical labels. Assumes that the .wrd files were made on wav files that did not have a befaft zero period.
This function can be used instead of the
get_label_vecs_from_filesmethod inside theAlignerclass if you only want a single file's label vector.- Parameters:
wrd_file (string, path to .wrd file)
length (int) -- length of stimulus (in samples) including befaft periods
fs (int, sampling rate)
befaft (array or list of length 2) -- containing befaft time periods in seconds
wrd_dict (dict) -- keys are words (capitalized) and values are integers which become the labels for each word
wrd_files_dir (string) -- Path to directory containing all the .wrd files to be included in the dictionary. This is ignored if wrd_dict is supplied, but otherwise, a new wrd_dict is created using the .wrd files in this directory. By default, this will make 'sp' (space) have a label of -1.
return_wrd_dict (bool) -- Whether or not to return the wrd_dict along with the labels as a tuple
- Returns:
labels (np.array, shape (time,)) -- Integer labels over time. Full length is befaft[0]*fs+length+befaft[1]*fs
wrd_dict (dict) -- Word dictionary (word to integer) used to create the labels. Only returned if return_wrd_dict==True
Build Word Dictionary from Set of Files¶
- naplib.features.create_wrd_dict(wrd_files_dir, list_to_skip=[])[source]¶
Create a new word to label dictionary, which can be passed to get_word_label_vector.
- Parameters:
wrd_files_dir (string) -- Path to directory containing all the .wrd files to be used
list_to_skip (list of strings, default=[]) -- Words which will not be added to the dictionary.
- Returns:
wrd_dict -- Dictionary of word:int (key:value) pairs for all the words in the corpus of files in the directory.
- Return type: