Encoding¶
TRF¶
- class naplib.encoding.TRF(tmin, tmax, sfreq, estimator=None, n_jobs=1, show_progress=True)[source]¶
Class for fitting temporal receptive field (TRF) models to one or more targets at a time. These can be encoding models (stimulus-to-brain) or decoding (brain-to-stimulus) models. This estimator used internally is sklearn.linear_model.RidgeCV() but can be specified as any estimator which implements the basic sklearn estimator API, including all estimators in sklearn.linear_model.
- Parameters:
tmin (float) -- The starting lag (inclusive), in seconds (or samples if
sfreq== 1).tmax (float) -- The ending lag (inclusive), in seconds (or samples if
sfreq== 1). Must be > tmin.sfreq (int) -- The sampling frequency used to convert times into samples.
estimator (sklearn.linear_model instance, default=RidgeCV()) -- Estimator to use for each target. Must be compatible with sklearn API for Regressors (i.e. have fit(), predict(), score() methods, and a coef_ attribute). The default is sklearn.linear_model.RidgeCV() with alphas=np.logspace(-2, 5, 6), scoring='r2', cv=5. This trains ridge regularized regressors with built-in cross-validation over the regularization parameter using 5-fold cross validation.
n_jobs (int, default=1) -- Number of parallel processes to use for fitting TRFs
show_progress (bool, default=True) -- Whether to show a tqdm progress bar for the fitting over the n-outputs in .fit()
- coef_¶
- Type:
np.ndarray, shape (n_targets[, n_features_y], n_features_X, n_lags)
Notes
For a causal system, the encoding model would have significant non-zero values only at positive lags. In other words, lags point backwards in time relative to the input, so positive lags correspond to previous time samples, while negative lags correspond to future time samples. In most cases, an encoding model should use tmin=0 and tmax>0, while a decoding model should use tmin<0 and tmax=0.
- fit(data=None, X='aud', y='resp')[source]¶
Fit a multi-output model to the data in X and y, which contain multiple trials.
- Parameters:
data (naplib.Data instance, optional) -- Data object containing data to be normalized in one of the field. If not given, must give the X and y data directly as the
Xandyarguments.X (str | list of np.ndarrays or a multidimensional np.ndarray) -- Data to be used as predictor in the regression. Should be of shape (time, num_features). If a string, it must specify one of the fields of the Data provided in the first argument. If a multidimensional array, first dimension indicates the trial/instances which will be concatenated over to compute normalization statistics.
y (str | list of np.ndarrays or a multidimensional np.ndarray) -- Data to be used as target(s) in the regression. Once arranged, should be of shape (time, num_targets[, num_features_y]). If a string, it must specify one of the fields of the Data provided in the first argument. If a multidimensional array, first dimension indicates the trial/instances.
- Returns:
self
- Return type:
returns an instance of self
- predict(data=None, X='aud')[source]¶
- Parameters:
data (naplib.Data object, optional) -- Data object containing data to be normalized in one of the field. If not given, must give the X data directly as the
Xargument.X (str | list of np.ndarrays or a multidimensional np.ndarray) -- Data to be used as predictor in the regression. Once arranged, should be of shape (time, num_features). If a string, it must specify one of the fields of the Data provided in the first argument. If a multidimensional array, first dimension indicates the trial/instances which will be concatenated over to compute normalization statistics.
- Returns:
y_pred -- Predicted target for each trial in X.
- Return type:
np.ndarray or list of np.ndarrays, each with shape (time, num_targets[, num_features_y])
- score(data=None, X='aud', y='resp')[source]¶
Get scores from predictions of the model. This uses the defualt score() method from the estimator used.
- Parameters:
data (naplib.Data object, optional) -- Data object containing data to be normalized in one of the field. If not given, must give the X and y data directly as the
Xandyarguments.X (str | list of np.ndarrays or a multidimensional np.ndarray) -- Data to be used as predictor in the regression. Once arranged, should be of shape (time, num_features). If a string, it must specify one of the fields of the Data provided in the first argument. If a multidimensional array, first dimension indicates the trial/instances which will be concatenated over to compute normalization statistics.
y (str | list of np.ndarrays or a multidimensional np.ndarray) -- Data to be used as target(s) in the regression. Once arranged, should be of shape (time, num_targets[, num_features_y]). If a string, it must specify one of the fields of the Data provided in the first argument. If a multidimensional array, first dimension indicates the trial/instances which will be concatenated over to compute normalization statistics.
- Returns:
scores -- The scores estimated by the model for each output.
- Return type:
np.array of float, shape (n_targets,)
- corr(data=None, X='aud', y='resp')[source]¶
Get correlation coefficient from predictions of the model.
- Parameters:
data (naplib.Data object, optional) -- Data object containing data to be normalized in one of the field. If not given, must give the X and y data directly as the
Xandyarguments.X (str | list of np.ndarrays or a multidimensional np.ndarray) -- Data to be used as predictor in the regression. Once arranged, should be of shape (time, num_features). If a string, it must specify one of the fields of the Data provided in the first argument. If a multidimensional array, first dimension indicates the trial/instances which will be concatenated over to compute normalization statistics.
y (str | list of np.ndarrays or a multidimensional np.ndarray) -- Data to be used as target(s) in the regression. Once arranged, should be of shape (time, num_targets[, num_features_y]). If a string, it must specify one of the fields of the Data provided in the first argument. If a multidimensional array, first dimension indicates the trial/instances which will be concatenated over to compute normalization statistics.
- Returns:
corrs -- The correlations of the predictions by the model for each output.
- Return type:
np.array of float, shape (n_targets,)
- set_fit_request(*, data: bool | None | str = '$UNCHANGED$') TRF¶
Configure whether metadata should be requested to be passed to the
fitmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- set_predict_request(*, data: bool | None | str = '$UNCHANGED$') TRF¶
Configure whether metadata should be requested to be passed to the
predictmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed topredictif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it topredict.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- set_score_request(*, data: bool | None | str = '$UNCHANGED$') TRF¶
Configure whether metadata should be requested to be passed to the
scoremethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Examples using TRF¶


BandedTRF¶
- class naplib.encoding.BandedTRF(tmin, tmax, sfreq, alphas=None)[source]¶
Iterative Banded Ridge TRF model.
Fits features sequentially in bands. For each band, the regularization (alpha) is optimized via leave-one-trial-out cross-validation using coefficient averaging for computational efficiency.
- Parameters:
- fit(data=None, X=['aud'], y='resp')[source]¶
Fit the Iterative Banded Ridge model using leave-one-trial-out cross-validation.
The model fits features sequentially according to feature_order. For each new feature band, an optimal regularization parameter (alpha) is selected from self.alphas by maximizing the average prediction correlation across held-out trials.
- Parameters:
data (naplib.Data instance, optional) -- Data object containing data to be normalized in one of the field. If not given, must give the X and y data directly as the
Xandyarguments.X (list of str | list of list of np.ndarrays) -- Data to be used as predictor in the regression. Should be a list, in which each element is a feature, corresponding to a list of trials, each of which is a numpy array of shape (time, num_features). If a string, it must specify a list of fields of the Data provided in the first argument.
y (str | list of np.ndarrays) -- Data to be used as target(s) in the regression. Once arranged, should be of shape (time, num_targets). If a string, it must specify one of the fields of the Data provided in the first argument.
- Returns:
self -- Returns the instance of the fitted model.
- Return type:
Notes
The cross-validation uses 'coefficient averaging' for efficiency. For each alpha in the sweep, a model is fit to each trial individually. The prediction for a held-out trial $i$ is generated using the mean coefficients of all trials $j neq i$.
- predict(data=None, X=['aud'])[source]¶
Predict target responses using the fitted Banded Ridge model.
This method performs Leave-One-Trial-Out (LOTO) prediction. For each trial in the input data, it averages the regression coefficients from all other trials (fitted during training) to generate the prediction for the current trial.
- Parameters:
data (naplib.Data object, optional) -- Data object containing data to predict from in one of the fields. If not given, must give the X data directly.
X (list of str | list of list of np.ndarrays) -- Data to be used as predictor in the regression. Should be a list, in which each element is a feature, corresponding to a list of trials, each of which is a numpy array of shape (time, num_features). If a list of strings, it must specify a list of fields of the Data provided in the first argument.
- Returns:
preds -- Predicted target values for each trial. Each element is an array of shape (n_samples, n_targets).
- Return type:
list of np.ndarray
- Raises:
ValueError -- If the model has not been fitted, or if the number of trials in data does not match the number of models in self.model_.
Notes
Because this model stores a separate fit for every trial to enable efficient cross-validation, the predict step requires the input to have a one-to-one mapping with the training trials.
- summary(channel=None)[source]¶
Generate a statistical report of feature contributions and model performance.
Calculates the incremental improvement (Delta R) for each feature band added to the model and performs a one-sample t-test (alternative='greater') across trials to determine if the contribution is significantly greater than zero.
- Parameters:
channel (int, optional) -- The specific target channel (e.g., electrode or sensor) to summarize. If None (default), results are averaged across all channels.
- Returns:
df -- A summary table indexed by 'Feature' containing: - Total R: Cumulative correlation after adding this feature. - Delta R: Incremental correlation increase attributed to this feature. - Alpha: The optimized regularization parameter for the band. - p-value: Significance of the Delta R across trials (t-test).
- Return type:
Notes
The Delta R for the first feature is its Total R. For subsequent features, Delta R is calculated as: $ Delta R_{n} = R_{n} - R_{n-1} $
Significant p-values suggest that the addition of a specific feature band significantly improves the model's predictive power on held-out data.
Examples using BandedTRF¶
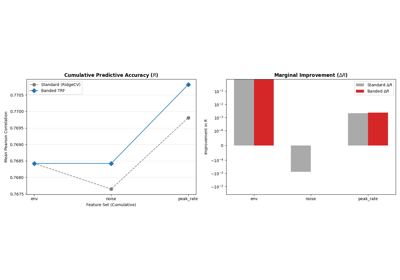
TRF Comparison: Iterative RidgeCV vs. Banded Regularization